페이지 랭크(Page Rank)란?
웹은 웹 페이지와 하이퍼링크로 구성된 방향성이 있는 그래프라고 볼 수 있습니다.
예를 들어, 네이버 -> 네이버 검색 -> 다른 사이트 -> ... 이런식으로 연결되어져있는 것이죠!
그렇다면 이런 웹 속에서 검색 엔진은 어떻게 만들어지는 것일까요?
구글 이전의 검색엔진
1. 웹을 거대한 디렉토리로 정리
- 웹 페이지 수가 증가함에 따라 수와 깊이가 무한정 커지는 문제점
- 카테고리의 구분이 모호하여 저장, 검색이 어려움
2. 웹페이지에 포함된 키워드에 의존한 검색 엔진
- 사용자가 입력한 키워드에 대해 해당 키워드를 여러 번 반복한 웹페이지 반환
- 악의적인 웹페이지에 취약 (임의로 특정 키워드 반복하여 사용)
그렇다면 사용자 키워드와 관련성이 높고 신뢰할 수 있는 웹페이지를 어떻게 찾을 수 있을까요?
바로 "페이지 랭크(Page Rank)"입니다!
페이지랭크의 핵심 아이디어는 "투표" 입니다.
즉, 투표를 통해 사용자 키워드와 관련성이 높고 신뢰할 수 있는 웹페이지를 찾는 것입니다.
그렇다면 투표는 대체 누가 할까요?
바로 웹페이지들이 합니다!
여기에서 투표는 "하이퍼링크"가 됩니다!
즉, A라는 페이지에서 B라는 페이지를 참조하고 있다면 A의 작성자가 판단하기에 B가 관련성이 높고, 신뢰할 수 있다는 의미입니다.
즉, A 페이지가 B 페이지에게 투표를 한 것이죠.
결국 특정 페이지에게 들어오는 간선이 많을수록 신뢰할 수 있는 페이지라는 의미입니다.
그러나 이것만으로는 불충분합니다.
악의적으로 웹 페이지를 여러 개 만들어 서로 참조하게 함으로써 간선의 수를 부풀릴 수 있으니까요.
그렇다면 이런 악용은 어떻게 막을 수 있을까요?
바로 "가중 투표"입니다.
관련성이 높고 신뢰할 수 있는 웹사이트의 투표에는 가중치를 주어 더 중요하게 간주하는 것입니다.
그런데 관련성이 높고 신뢰할 수 있는 웹사이트를 정하기 위해 투표를 하는 것인데, 이렇게 되면 출력이 입력이 되는 것 아닌가??
맞습니다! 바로 재귀를 사용해서 이를 해결할 것입니다.
각 웹 페이지는 각각의 나가는 이웃에게 $\frac{자신의 페이지 랭크 점수}{나가는 이웃의 수}$ 만큼의 가중치로 투표를 하게 됩니다.
또한 여기서 페이지 랭크 점수란 받은 투표의 가중치 합으로 결정이 됩니다.
다음과 같은 웹페이지 그래프가 있다고 가정해봅시다.
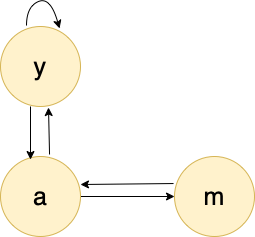
이 예시에서 정점 별 페이지 랭크 값은 다음과 같습니다.
$r_y = \frac{r_y}{2} + \frac{r_a}{2}$
$r_a = \frac{r_y}{2} + {r_m}$
$r_m = \frac{r_a}{2}$
한 번 직접 계산해보세요! 아주 간단하죠?
페이지 랭크 임의 보행(Random Walk)의 관점에서 살펴보기
웹 서퍼(웹을 방문하는 사람)는 임의 보행, 즉 랜덤하게 웹 페이지들을 이곳저곳 방문을 합니다.
즉, 현재 웹 페이지에 있는 하이퍼링크 중 하나를 균일한 확률로 클릭하는 방식으로 웹을 방문한다고 가정합니다.
이때 웹 서퍼가 $t$번째 방문한 웹 페이지가 $i$ 일 확률을 $p_i(t)$라고 하면
$p(t)$는 길이가 웹 페이지 수와 같은 확률분포 벡터가 됩니다.
그러면 다음과 같은 식을 만족하게 됩니다.
$$p_j(t+1) = \sum_{i\in{N}_{in}(j)} \frac{p_i(t)}{d_{out}(i)}$$
$p_j(t+1)$이란 웹 서퍼가 t+1번째 방문한 웹페이지가 j일 확률입니다.
그럼 t+1에 j를 방문하려면 t번째에는 웹 서퍼가 어디에 있어야 할까요?
바로 j를 하이퍼링크로 가지고 있는 웹 페이지에 있어야 합니다.
따라서 오른쪽 항에 $p_i(t)$가 바로 t번째에 j의 이웃 i에 있을 확률인 것입니다.
그럼 i에 있는 여러 하이퍼링크 중에 j로 가기 위해서는 $\frac{1}{d_{out}(i)}$, 즉 i에서 나가는 여러 간선($d_{out}(i)$)중 하나, j가 선택될 확률을 곱해주어야 하므로 위와 같은 식이 나오는 것입니다.
생각보다 더 그럴듯하고 간단하죠??
웹 서퍼가 이 과정을 무한히 반복, 즉 t가 무한히 커지면 확률분포 $p(t)$는 수렴하게 됩니다.
즉, $p(t) = p(t+1) = p$가 성립하게 되고, 이 $p$는 정상 분포(Stationary Distribution)이라고 부릅니다.
$$p_j = \sum_{i\in{N}_{in}(j)} \frac{p_i(t)}{d_{out}(i)}$$
즉, 정리해보면 투표 관점에서 정의한 페이지 랭크 점수 $r$
$$ r_j = \sum_{i\in{N}_{in}(j)} \frac{r_i}{d_{out}(i)}$$
random walk 관점에서 정의한 정상 분포 $p$
$$p_j = \sum_{i\in{N}_{in}(j)} \frac{p_i(t)}{d_{out}(i)}$$
두 개의 수식이 완벽하게 동일합니다!
즉, 투표 관점에서 정의한 수식은 이미 랜덤 워크 관점에서 정의한 것과 완전히 동일하니 논리적으로 의미가 있다는 것을 알 수 있게 된 것입니다!
본 글은 부스트코스 "그래프와 추천 시스템" 강의를 듣고 공부하며 정리 및 재구성한 글입니다.
그래프와 추천 시스템
부스트코스 무료 강의
www.boostcourse.org
'DL & ML > Graph' 카테고리의 다른 글
| [DGL] Graph와 Heterogeneous Graph의 차이 (0) | 2022.02.04 |
|---|---|
| [그래프와 추천 시스템] 페이지 랭크 계산하기 (0) | 2022.02.02 |
| [그래프와 추천 시스템] 그래프 패턴 - 다양한 그래프 패턴 (0) | 2022.01.28 |
| [그래프와 추천 시스템] 그래프 패턴 - 실제 그래프와 랜덤 그래프 (0) | 2022.01.28 |
| [그래프와 추천 시스템] 그래프의 유형 및 분류 (0) | 2022.01.28 |


