본 글은 논문을 읽고 공부를 하는 과정에서 이해한 바를 번역 / 설명 해둔 글입니다.
혹시 동일 논문을 읽는 다른 분들께 도움이 되었으면 하여 정리해두나 잘못된 부분이나 부족한 부분이 있을 수 있습니다.
따라서 잘못된 부분 / 궁금한 부분이 있으면 언제든지 댓글 환영합니다.😄
Recsys 2021 온라인 학회에서 본 논문을 알게 되었다.
GNN을 활용한 추천 시스템에 막 관심이 생길 무렵 학회를 듣게 되었고, 그래서 해당 논문이 눈에 띄었다.
특히 모델 이름이 "코기"라는 점이 참 귀여워서 더 궁금해지는 논문이었다. 🐶
CoRGi: Content-Rich Graph Neural Networks with Attention
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation,
arxiv.org
0. 요약
타겟 도메인에 대한 그래프의 표현방법은 엔티티(nodes), 관계(edges)로 나타낼 수 있다. 그러나 이런 식의 표현 방법은 중요하고 풍부한 정보들을 잃기 쉽다.
예를 들어, 영화 추천 데이터셋을 생각해보자.
사용자와 영화의 관계를 이분 그래프로 표현하는 가장 간단한 방법은 사용자와 영화를 각각 노드로 보고, 관계(선호 여부)를 edge로 연결짓는것이다.

그러나 이러한 그래프 표현방법의 문제점은 item에 담겨있는 풍부한 정보들을 사용할 수 없다는 것이다.
단순히 사용자와 영화 사이의 연결관계 뿐 아니라, 영화에 담겨있는 의미(장르, 감독, 연도 등)가 추천에 있어서 중요하게 영향을 미칠 수 있으나 이들이 무시된다는 것!
또는 이를 간단한 single vector로 요약하여 GNN의 초기값으로 사용하는 정도로 활용 가능하다.
따라서 본 논문에서는 노드 이웃들의 풍부한 정보를 고려하는 GNN모델, CoRGi를 제안한다. 🐶
HOW?
각 노드의 정보에 대해 개인화된 attention mechanism을 사용한 message passing을 도입하여
아이템에서 나타나는 words에 대해 user-item-specific attention scores를 할당했다.
본격적으로 논문 내용을 하나씩 살펴보자!
1. Introduction
GNN은 딥러닝 연구에서 큰 성공을 거두었습니다. GNN을 통해 복잡한 그래프 구조의 데이터를 모델링할 수 있게 되었죠.
반면 그래프 표현방법은 매우 합리적임에도 그래프를 형성하는 과정에서 데이터의 손실이 존재한다는 단점이 있습니다.
위에서 설명했던 예제 뿐만 아니라, 책을 추천하다고 했을 때에도 사용자와 노드 사이의 평점은 표현할 수 있을지 몰라도 각각의 책 노드가 가지고 있는 풍부한 콘텐츠 정보들(텍스트 그림, 표 등등..)은 표현이 불가능합니다.
추천에 있어서 이러한 정보들이 성능 향상을 하는데에 매우 중요함에도 불구하고 말이죠.
GNN에 nodes의 content 정보를 통합하는 가장 기초적인 방법은 관련 정보를 하나의 벡터(임베딩)로 요약하는 것입니다.
트랜스포머 또른 bag-of-words 같은 인코더 모델을 사용하여 전체 문장 / 문서로부터 하나의 벡터를 계산하는 것이죠.
그러나 이러한 방법은 차선책에 불과합니다. 외부적으로 사전 계산이 되어야 하며, 벡터의 크기도 상대적으로 작기 때문입니다.
이는 물론 NLP 연구쪽에서는 많이 사용됩니다.
입력을 하나의 벡터/임베딩으로 표현하는 대신 전체 입력을 사용합니다. 출력을 생성할 때에도 인코더 - 디코더 모델이 주어진 전체 입력에 대해 attention mechanism을 사용합니다.
예를 들어 NLP 분야 중 텍스트 요약에서 디코더는 전체 입력 텍스트에 있는 모든 단어의 인코딩 된 표현에 대해 attention을 하게 되죠.
이처럼 GNN에서도 단순 하나의 요약된 벡터 사용 또는 외부적으로 계산된 벡터가 아닌 GNN 과정 속에서 그래프 내의 노드의 content 정보를 잘 잡아낼 수 있는 더 나은 방법이 필요합니다.
이를 위해 본 논문에서는 CoRGiContent-Rich Graph neural network with attention)🐶을 제안합니다.
CoRGi는 edge represntations을 계산 할 때에 각 노드의 풍부한 content에 대해 attention mechanism을 사용하는 message-passing GNN입니다.
CoRGi를 적용해 볼 수 있는 방법 중 하나는 edge-value 예측입니다.
예를 들어, 아래와 같이 user와 item 사이 missing edge 값을 예측하는 GNN이 있다고 가정해봅시다.

만약 student-question answers에 대한 데이터셋이라고 하면 item은 질문이 될 것입니다.
각 질문들은 풍부한 텍스트 설명으로 표현되겠죠?
그러나 그래프 표현 방식에서는 학생과 질문 사이에 학생의 response를 기반으로 하여 풍부한 상호작용을 찾아낼 수는 있지만 질문에 대한 내용은 무시되게 됩니다.
그러나 CoRGi는 개인화된 어텐션 메커니즘을 통해서 아이템 컨텐츠의 user-item pair-specific representation을 생성하게 됩니다.
이는 edge value에 대해 더 좋은 예측으로 이어질 수 있겠죠?
즉, 요약하자면 본 논문은 아래와 같은 내용입니다.
1) CoRGi : 노드 컨텐츠에 대해 어텐션 메커티즘을 포함한 message-passing GNN
2) CorGi를 user-item 추천 task에 전문적으로 사용
3) 베이스라인과 비교하여 CoRGI가 더 나은 예측 성능을 보여준다는 것, 특히 user rating을 많이 받지 못한 아이템에 대해서는 더욱 중요한 역할을 한다는 것을 보여줌
2. CoRGi : GNNs with attention over node content
자, 이제 본격적인 구조와 구현에 대해 알아보겠습니다.
먼저, 아래 표에 본 논문에서 쓰이는 주요 표기법들이 나와있으니 참고해주세요!

(a) Graph sets & elements : 말 그대로 graph set과 elements를 위한 표기법
(b) CoRGi variables : CoRGi 모델에서 사용할 변수와 파라미터
(c) Content-related notations : content/ item node를 묘사하는 표기법
추가적으로, CoRGi의 message passing을 하는 동안 사용되는 학습가능한 가중치 값들이 있습니다.
1) 노드 임베딩을 업데이트 할 때 사용 : $P^{(l)}, Q^{(l)}$
2) attention coefficients를 계산할 때 사용 : $W^{(l)}_U, W^{(l)}_M, p^{(l)}$
3) 예측하기 위한 MLP에 사용 : $w_{out}, b$
Problem setting.
그래프 $G = (V, E)$가 있습니다.
각 노드 $v \in V$ 와 연관된 features는 $h_v$, 각 edge에 연관된 features는 $e^{(0)}_{ij}, \forall (i, j) \in E$ 라고 표현합니다.
만약 노드 또는 엣지가 어떠한 features와도 연관이 없으면 상수가 배정될 것입니다.노드의 부분집합 $V_C \subset V$ 는 contents nodes set을 의미하는데요, 이들은 content vector representations $Z_i = \left\{z^{(i)}_1, ..., z^{(i)}_{n(i)} \right\}, \forall v_i \in V_C, z^{(i)}_k \in \mathbb{R}^D$ 로 이루어져있습니다. 말 그대로 content vector들로 이루어졌다는 뜻이라고 보면 될 것 같습니다.여기에서 $n(i)$는 각 노드 $v_i$에 연관된 컨텐츠 벡터의 수이며, 노드마다 달라질 수 있습니다. $z^{(i)}_k$는 모델의 직접적인 입력이 되거나 트랜스포머와 같은 다른 딥러닝 요소의 출력 값이 될 수도 있습니다.
CoRGI의 목표는 각 노드 내의 content vectors 집합을 고려하여 노드와 엣지의 표현을 학습하는 것입니다.
CoRGi.
CoRGi는 그래프와 노드 내의 정보를 사용하여 노드와 엣지의 임베딩을 학습하게 됩니다.
CoRGi는 일반적인 message passing GNN 구조를 따르고 있으며, GRAPE 모델과도 유사합니다.
그러나 존재하는 모델들과 달리 CoRGI는 개인화된 attention을 사용하여 message-passing을 하는 동안에 각 노드와 연관된 content vector representations를 사용한다는 차이점이 존재합니다.
특히, attention mechanism을 사용하여 이웃 노드들의 문맥에 따라 같은 컨텐츠여도 서로 다른 부분에 집중하여 학습을 하게 됩니다.

그림을 살펴봅시다.
학생이 users, 아이템이 questions라고 가정한 이분 그래프입니다. 이때 궁극적인 목표는 사용자와 아이템 사이에 있는 edge 값을 예측하는 것입니다.
당연히 몇몇의 edge에 대해서는 이미 알려져있고, 몇몇은 모르는 상태겠죠?
이때의 edge representation은 오른쪽 그림과 같이 GNN message-passing layer를 통해 계산이 됩니다.
먼저 질문을 표현하는 content information이 모델 F(ex. transformer)를 통과하면 인코딩 된 content 정보로 표현이 가능해지고, CoRGi에서는 이를 content vector로 사용하게 됩니다.
이때 edge의 임베딩 (eg. $e_{{u_1}m}$)은 사용자의 노드 임베딩 (e.g. $h_{u_1}, h_{u_2}$)와 $\left \{z_k\right\}^{n(m)}_1$ 의 attention mechanism을 사용하여 계산하게 됩니다.
그러면 동일한 컨텐츠 정보임에도 사용자 노드 임베딩에 따라서 서로 다른 부분에 attention을 하게 되고, 이를 통해 개인화된 방식으로 edge representation을 계산할 수 있게 되는 것입니다.
이번에는 수식과 알고리즘적으로 살펴보겠습니다.

CoRGi는 대부분의 GNN 모델 처럼 L개의 message passing layers로 구성이 되어있습니다.
각 layer $l$에서, CoRGi는 노드 $v_j$로부터 $v_i$로 가는 message $m_{ij}^{l}$를 이전 단계의 노드 임베딩 $h_{j}^{(l-1)}$와 edge embedding $e_{ij}^{(l-1)}$를 통해 구하게 됩니다.

즉, 노드 $v_i$로 오는 메세지는 노드 $v_i$의 이웃 노드인 $v_j$들간의 edge embedding과 $v_j$의 node embedding의 concat 된 값이라는 거죠.
참고로 노드 임베딩의 초기값 $h^{(0)}_i$과 엣지 임베딩의 초기값 $e^{(0)}_{ij}$는 input node feature와 input edge attributes로 설정합니다.
이렇게 연결된 이웃 하나하나마다 메세지를 계산했으면, 이 메세지들을 모두 aggregate하여 $v_i$의 노드 임베딩을 업데이트 합니다.

이렇게 메세지를 구하는 방법은 "Handling misssing data with graph representation learning" (You et al., 2020) 논문에서 나온 방식과 동일하다고 합니다.
그러나 CoRGi만의 방법은 여기서부터입니다. CoRGI는 각각 노드의 content 정보를 어떻게 사용할지에 관심이 있으니까요!
이제부터 GNN message passing에서 attention mechanism을 사용하는 방법에 대해 설명하겠습니다.
attention mechanism을 통해 CoRGi는 메세지가 컨텐츠의 특정 파트에 집중 할 수 있게 해줍니다.
이러한 능력은 몇몇 시나리오에서 굉장히 도움이 될 것입니다.
예를 들어, 교육 추천 시스템을 생각해봅시다.
질문의 내용은 학생이 해당 질문에 제대로 답변을 할 수 있는 능력이 있는가를 예측하는데에 매우 중요한 요소입니다.
물리를 잘하는 학생이 있고, 국어를 잘하는 학생이 있을테니까요!
학생들의 스킬에 따라서 초점을 맞추는 것은 다양해질수가 있는데요, 주제를 정확하게 학습한 학생은 key information에 초점을 맞추는 반면, 잘 모르는 학생은 엉뚱한 곳에 초점을 맞출 수 있겠죠?
CoRGi의 attention mechanism은 이러한 효과를 내는 것을 목표로 합니다.
attention mechanism을 모델링하기 위해 모든 edge features $e^{(0)}_{ij}$와 content-attention vectore $e^{(l)}_{ij, CA}$를 combine해야 합니다.
combine을 하는 데에는 여러가지 방법이 있는데요, 본 논문에서는 위에 방법 포함 크게 두 가지 방법을 고려했다고 합니다.
(a) element-wise addition, 즉 $e^{(l)}_{ij} = e^{(l)'}_{ij} + e^{(l)}_{ij, CA}$
(b) concatenation opertaion, $e^{(l)}_{ij} = CONCAT(e^{(0)}_{ij}, e^{(0)}_{ij, CA})$
(a) 방법에서의 $e^{(l)'}_{ij}$는 아래와 같이 구할 수 있습니다.
이는 content 정보가 들어오기 전의 edge embedding을 의미합니다.
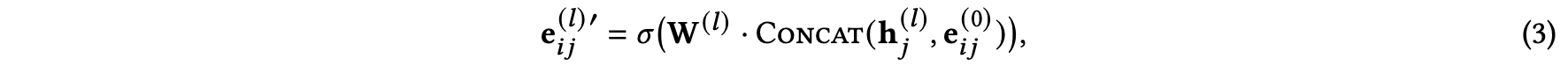
본 논문의 section 4.2를 보면 두 가지 방식에 대한 성능 비교가 있으니 궁금하신 분들은 참고하세요!
그러면 attention mechanism을 사용한 엣지 임베딩 $e^{(l)}_{ij, CA}$는 어떻게 구할 수 있을까요?
이는 content-attention vector $e^{(l)}_{ij, CA}$는 content $Z_{v_j}$에 attention mechanism을 사용하여 계산하게 됩니다.
정확히는 $v_j$의 content vector 집합과, $Z_j$, 그리고 이전 레벨 노드 임베딩 $h^{(l-1)}_i$를 사용하여 구하게 됩니다.
즉, 아래 식을 참고하면 되겠습니다.
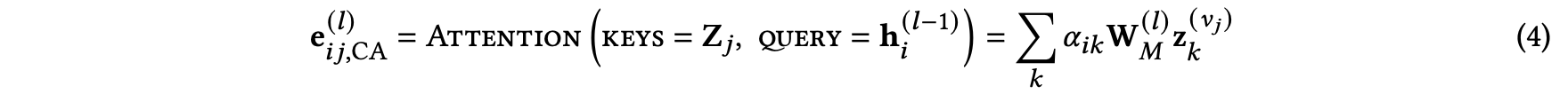
여기서 $a_{ik}$는 attention probability를 의미합니다.
attention probability의 경우 아래 식을 통해 구할 수 있습니다.
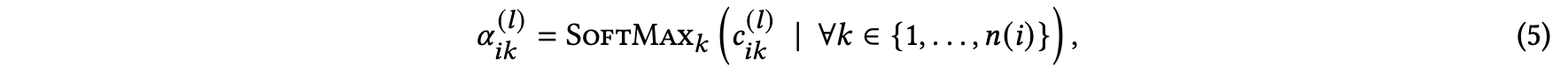
즉, attention score $c^{(l)}_{ik}$에 대한 softmax라고 보면 됩니다.
그렇다면 attention score는 어떻게 구할 수 있을까요?
본 논문에서는 두 가지 방법으로 테스트를 진행했다고 합니다.
1) concatenation (CO)
2) dot-product (DP)

자, 알고리즘을 정리해보면
1. 노드 i의 이웃들 사이의 메세지를 구합니다.
2. 메세지를 concat 하여 노드 i의 임베딩을 업데이트 합니다.
3. 노드 i의 이웃들에 대해서 content attention scores를 구합니다.
4. 3번에서 구한 attention score에 softmax를 하여 attention probability를 구합니다.
5. content 정보가 들어가지 않은 edge embedding을 아이템 임베딩과 초기 edge embedding을 concat하여 구합니다.
6. 4번에서 구한 attention probability를 사용하여 content-attention edge embedding을 구합니다.
7. 5번과 6번에서 각각 구한 edge embedding을 더하여 노드 i와 노드 j 사이의 최종 edge embedding을 계산합니다.
이 과정을 통해 최종적으로 나오는 출력은 모든 노드들에 대한 노드 임베딩을 구하게 됩니다.
Content representations.
본 논문에서 사용되는 content representation vectors $z^{(v_i)}_j$는 딥러닝 모델 F를 통해 구할 수 있습니다.
CoRGi 논문에서는 F의 구조에 대해 제한을 두지 않습니다.
예를 들어, 노드 content가 이미지라면 CNN-based 구조가 될 것이며, text라면 NLP 모델을 사용하게 될 것입니다.
2.1. CoRGi for user-response prediction
이제 위에서 구한 임베딩을 기반으로 사용자의 반응을 예측해봅시다.
$G = (V, E)$인 이분 그래프가 있고, 여기서 노드 집합 $V$는 $V_U \cup V_M$, 즉 사용자와 아이템의 노드 집합으로 이루어져있다고 가정합시다.
또한 각각의 아이템 노드들은 텍스트 정보 $D_m = [w^{(m)}_1, ..., w^{(m)}_{n(m)}]$, 즉 sequence of words 정보를 가지고 있습니다.
이러한 sequence는 encoder 모델 (F, 예를 들면 트랜스포머)을 사용하여 content vectors $Z_m$으로 변환이 가능하며 변환된 벡터가 CoRGI의 input으로 들어가게 됩니다.
사용자 노드 $v_u$와 아이템 노드 $v_m$ 사이의 edge를 예측하기 위해서는 GNN의 output으로 나온 user와 item node embedding을 concat하여 아래의 layer를 통해 구할 수 있습니다.

3. Related Work
이번에는 추천 시스템의 다른 모델에 대해 살펴보겠습니다.
Missing value imputataion : 아직 알지 못하는 값을 예측해서 채워넣은 것을 말합니다.
즉, 추천 시스템에서는 어떤 사용자가 특정 아이템에 대해서 어떤 반응을 할지 모르는 상황에 값을 예측하는 문제라고 볼 수 있겠죠.
추천 시스템에서는 수많은 collaborative filtering 방식과 matrix factorization 방법, 그리고 deep learning-based 방식으로 점점 발전을 해나가고 있습니다. 대표적으로는 아래와 같은 모델들이 있습니다.
DMF (Deep Matrix Factorization) : 입력 행렬을 MLP에 직접 사용하는 모델
VAE (Variation Autoencoders), VAEM (paretial-VAE model) : encoder-decoder-based로 결측값을 예측하는 문제
이런 모델들과 다르게 CoRGi는 node content와 같은 추가적인 정보를 활용합니다. 또한 content의 각 부분은 사용자마다 서로 다른 가중치 값으로 사용됩니다.
이번에는 그래프를 사용한 추천 모델들에 대해 알아봅시다.
지난 시간 동안, 그래프를 모델링하기 위해서 엔티티를 그래프의 nodes로, 엔티티 간의 관계는 edges로 사용해왔습니다.
GCN (graph convolutional networks) 모델은 노드의 잠재적인 rerpreentations를 학습하기 위해 convolutionaal neural network를 사용한 모델입니다.
GraphSAGE 모델은 그래프의 일부분에 대해서 학습을 진행할 수 있게 확장한 GCN 모델로 inductive한 환경에서 사용할 수 있게 만들어진 모델입니다.
GC-MC (graph convolutional matrix completion) 모델은 edge labels을 모델의 입력으로 사용하는 GCN의 변형 모델입니다.
다른 모델들과 다르게 GC-MC는 single-layer message-passing 구조를 사용하였으며 각 라벨은 별도의 message passing channel을 통해 전달됩니다.
GRAPE 모델은 GCN에 edge embeddings를 적용한 모델이며 모든 message-apssing layers에 대해 edge dropout을 적용합니다.
LightGCN 모델은 feature transformation과 비선형 활성화함수와 같이 추천 시스템에 이익이 아니라고 생각되는 부분을 간략화 또는 생략하고 대신 neighborhood aggeregation을 강조한 GCN 모델입니다.
이전에 제안되었던 추천 시스템에서의 GNN 모델과 비교해보면 CoRGi는 노드의 풍부한 컨텐츠 정보를 사용하여 모델링을 진행합니다.
PinSAGE같은 모델 역시 노드의 컨텐츠 정보를 사용하는 GCN 모델인데요, CoRGi는 여기에 한 노드와 다른 노드 사이 attention mechanism이 추가된다는 차별점이 있습니다.
따라서 CoRGi는 user-item 별로 attention probability를 계산하고, 이는 다시 edge embedding을 업데이트하는 데에 사용이 됩니다.
그래프에서 attention을 사용한 GATs(graph attention networks) 모델도 있습니다. GATs의 경우 attention을 타겟 노드가 source nodes로부터 오는 여러 개의 message를 구별하는데에 사용이 되어집니다.
CoRGi는 attention을 사용하지만 GATs처럼 각 노드의 이웃에 사용하는 것이 아닌 각 노드 내부 content에 사용한다는 차이점이 있죠.
4. Evaluation

본 논문의 item의 content를 그대로 사용하는 것이 아니라 동일한 content라고 하더라도 사용자마다 다른 값을 사용한다는 점이 재미있었다. 이를 통해 더욱 개인화된 좋은 성능의 추천을 제공할 수 있다는 것!
확실히 같은 content를 가지고 있다하더라도 사용자마다 받아들이는 것이 다르니 이를 attention을 통해 접근한다는 아이디어가 좋은 것 같다.
최근에 graph 관련 추천 시스템에서 어떻게 side information을 효과적으로 다룰 수 있을지에 대한 고민을 하고 있는데 도움이 많이 될 것 같다.
'DL & ML > Recommender System' 카테고리의 다른 글
| 추천시스템을 위한 데이터셋 (0) | 2021.11.23 |
|---|